英特爾(Intel)執行長陳立武(Lip-Bu Tan)在 Computex 2026 的演講讓企業將面對的三個問題同時進入一個框架下,提醒了企業必須提前規劃。這個框架本身,或許比任何具體的產品選擇更值得 CIO 帶走。
編撰/何信達
代理型 AI(Agentic AI)正以前所未有的速度重塑企業基礎架構。當 AI 工作負載從單純的「提示與生成」轉向自主規劃與執行的「任務導向」,傳統以 GPU 為絕對核心的算力配置將可能面臨不同瓶頸。本文藉由英特爾在 Computex 2026 的演講,導引出企業梳理算力比例、推論架構與資料治理上的三大關鍵決策挑戰。
三個正在失效的標準答案
下一輪基礎架構建置該怎麼做?過去市場上可能是這樣的答案:算力配置抓 1 比 7(GPU 負責運算)、推論流程交給同一批 GPU 跑到底、資料去留靠人工設定邊界。
但這三個答案正在失效。失效的原因不是硬體規格改變了,而是跑在這些硬體上的工作負載變了。
當企業開始部署 Agentic AI——不是讓員工查詢資訊的那種,而是接收目標、自主規劃、持續執行多步驟任務的那種——推論流程(inference pipeline)的結構就跟過去不一樣了。Agent 在執行過程中需要呼叫工具、讀寫檔案、進行合規查核,這些工作 GPU 不擅長,CPU 才是主角。Intel 在 Computex 演講中提出的數據是:Agentic AI 工作流程下,CPU 與 GPU 的比例接近 1 比 1,甚至偏向 CPU。
工作負載的改變牽動的不只是採購清單,它更直接逼出了 CIO 必須重新回答的三個連動問題:
- 第一、算力配置的比例該如何調整?
- 第二、推論流程要在什麼樣的架構下執行?
- 第三、當 agent 碰觸企業最敏感的資料時,治理的防線該建在哪裡?
第一、算力怎麼配——過去的配比為什麼可能失效
1 比 7,這個比例從哪裡來? 它不是某份規格書的建議值,而是過去幾年 AI 基礎架構建置的實際結果。傳統 AI 推論的邏輯單純:一個提示進入模型,模型運算,輸出答案。這個過程高度仰賴 GPU 的平行運算能力,CPU 的角色相對邊緣——負責排程、資料搬移、系統管理,幾乎不參與核心運算。1 比 7 的比例,是這個邏輯的自然產物。
Agentic AI 改變的不是模型,而是任務的類型。 一個 agent 接收到目標之後,它不是產生一個答案就結束。它會規劃步驟、呼叫外部工具、讀取檔案、執行程式碼、查核合規條件、根據結果調整下一步——然後循環。這些動作裡,有大量的工作屬於序列性邏輯處理,而不是大規模平行浮點運算。前者是 CPU 的強項,後者才是 GPU 的強項。
[ 加入 CIO Taiwan 官方 LINE 、 Facebook 與 LinkedIn,與全球CIO同步獲取精華見解 ]
演講中一個開發場景具體說明了這個差異:要求 AI 撰寫一段呼叫 API 的 Python 程式碼。傳統推論模式下,GPU 主導全程。切換到 Agentic AI 系統後,任務被拆解——語法檢查(linting)交給 Xeon 6 Plus 的效率核(E-core)、網頁擷取與編譯交給效能核(P-core)、單元測試再回到效率核。結果是 CPU 與 GPU 的比例接近 1 比 1,而且偏向 CPU。
這個數字獲得獨立分析師的支持。Intel 官方新聞稿引用 Creative Strategies 首席分析師 Ben Bajarin 的說法:訓練時代的部署比例接近一 CPU 對四 GPU,Agentic 推論則將這個關係轉變為大約 1 比 1,甚至更少 GPU。
對 CIO 而言,這個比例變化的意涵是直接的:如果企業的 AI 應用正在從查詢式走向任務式,現有以 GPU 為中心設計的基礎架構,便可能有配置失當的疑慮。而且這個問題不會在跑分測試裡顯現,只會在 agent 實際執行複雜任務時,以延遲與瓶頸的形式浮現。
第二、推論該怎麼做——拆解式推論從研究走進部署
算力配置是第一個難題,而緊接而來的架構挑戰是:推論流程(inference pipeline)本身,要怎麼設計?
傳統做法的邏輯是讓同一批 GPU 包辦全程。前期的「預填充」(prefill)階段需要大量平行運算,GPU 擅長;後期的「解碼」(decode)階段是序列性逐步生成,GPU 的優勢大幅縮水,卻仍在消耗同等算力與電力。
業界對這個問題的回應,是把推論流程拆開——由最適合各個階段的晶片分別承擔,而非讓同一類硬體包辦所有事。這個做法業界稱為 Disaggregated Inference(拆解式推論)。這個概念在 2026 年已從研究走進實際部署,不再是技術預覽,而是可採購的現實選項。
Intel 在 Computex 展示的,正是這個方向的跨供應商商業落地版本:由 Intel Xeon 6 統籌編排,搭配合作夥伴的 AI 晶片與 GPU 各司其職。根據第三方機構 Artificial Analysis 測試,這種拆解式架構的端到端延遲,比純 GPU 架構快上 2 至 3 倍。
但選擇 Disaggregated Inference 的代價是管理複雜度的大幅上升。Deloitte Tech Trends 2026 指出,企業現有基礎架構正轉向雲端、本地端與邊緣運算的策略性混合架構,重建過程需要模組化架構與嵌入式治理,也就是運用靈活的雲端原生平台、打破資料孤島,並將安全與監督直接寫入底層。這些複雜度不會因為效能數字好看就自動消失,它需要有人承擔。
第三、資料的邊界在哪裡——混合代理推論的治理意涵
前兩個問題——算力怎麼配、推論怎麼設計——本質上都是效能與成本的優化問題。第三個問題的性質不同,它是一個治理問題:當 AI agent 開始主動接觸企業最敏感的資產,運算發生在哪裡,就是該治理的地方。
這個問題在企業 IT 的討論裡並不陌生。雲端時代已經有過一輪「哪些資料可以上雲」的辯論,各產業都建立了自己的邊界。但 Agentic AI 把這個問題推進了一步:過去是「資料存在哪裡」,現在變成「推論發生在哪裡」。一份保密文件放在本地伺服器,不等於 AI 分析它的過程也發生在本地。
市場目前的主流回應,是讓使用者手動設定哪些任務留在本地、哪些送往雲端。這個做法的問題顯而易見:它把一個需要逐任務、逐資料判斷的複雜決策,交給不具備技術背景的使用者承擔。
[ 推薦閱讀:黃仁勳演講,有哪些 Agentic AI 架構認知你需要更新? ]
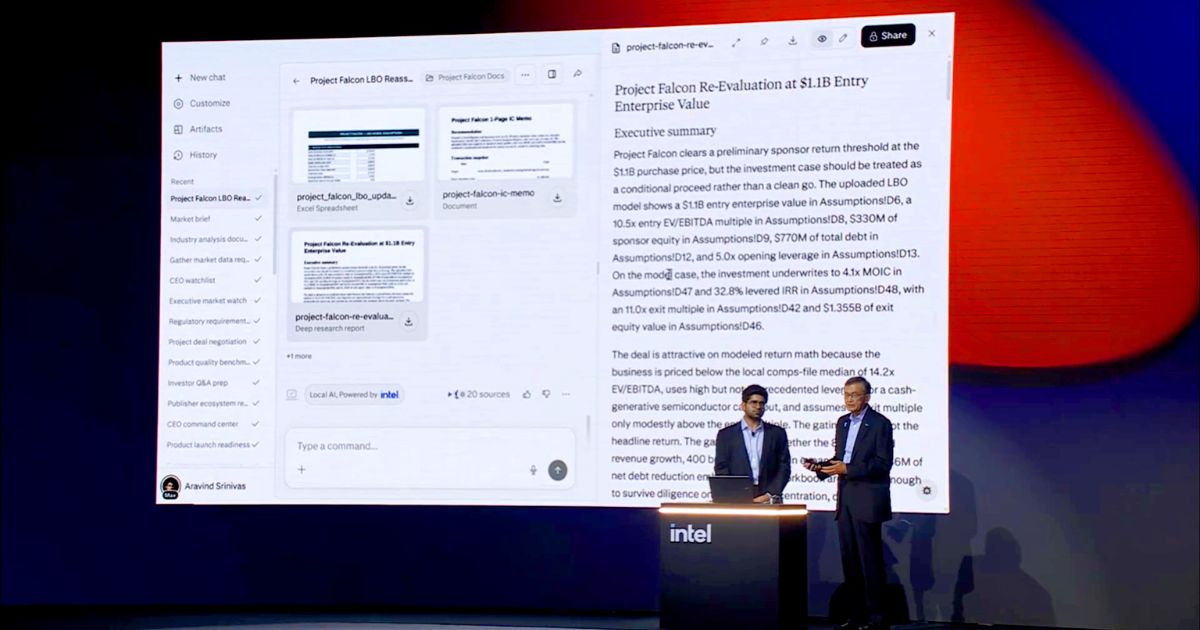
執行長陳立武與 Perplexity 創辦人 Aravind Srinivas 在演講中展示的方向,是讓系統自動做這個判斷。Perplexity Computer 定位為「AI 作業系統」,能調用最多 20 個不同模型跨工具、跨檔案協作編排,核心設計是讓系統逐任務自動決定執行位置——敏感的留在本地,其餘的送往雲端——不需要使用者事先選擇。
演講示範的場景是私募股權公司的盡職調查:分析師處理代號「Project Falcon」的保密專案,材料涵蓋私募交易文件、NDA、財務模型與雙語逐字稿。本地端模型運行於 Core Ultra Series 3 的 GPU 上,負責讀取文件、判斷敏感度分級,並決定哪些內容可以離開裝置。研究 agent 可在不暴露私密文件的前提下對外查詢補充資訊,最終由雲端大模型協助生成報告,但機密資料從未離開裝置。
Perplexity 創辦人 Aravind Srinivas 將這套架構的核心邏輯概括為「最大化每瓦每用戶的 token 價值」(token value per watt per user)。這個表述揭示了混合推論另一個值得關注的面向:它不只是隱私保護的手段,也是成本控制的工具。本地端執行小模型處理篩選與分級,雲端只承擔真正需要前沿模型能力的任務——這個分工邏輯,與企業 IT 對推論成本的關切直接呼應。
根據 Deloitte《2026 企業 AI 狀態》報告,Agentic AI 使用量在未來兩年內將急遽上升,但目前僅五分之一的企業擁有成熟的自主 AI 代理治理模式。這個現狀意味著「推論發生在哪裡」這個問題,遲早會從技術決策上升為 CIO 與法務、合規團隊必須共同定義的政策邊界。
三個問題,CIO 必須提前思考
面對這三個挑戰,CIO 與 IT 團隊需要的是提前思考,而非等待標準答案。
算力比例的問題,市場有了方向但沒有唯一解——1 比 1 是一個參考座標,不是採購規格。推論架構的問題,技術方向已經收斂,Disaggregated Inference 從研究走進部署,但管理複雜度的代價仍需審慎評估。資料治理邊界的問題,需求真實存在,而市場的解法仍在早期驗證階段。
這三個問題有一個共同的特徵:它們不能分開考量。算力比例影響推論架構的設計選擇,推論架構決定資料在哪個環節流動,而資料流動的邊界又會回頭約束算力可以怎麼配置。
這意味著,Agentic AI 帶來的基礎架構挑戰,本質上是一個系統設計問題,而不是三個獨立的採購決策。過去 AI 基礎架構可以分批、分部門、分預算週期處理。但當工作負載從查詢式走向任務式,切片式的決策方式將會產生系統性的盲點。
不妨用這三個問題提前檢視組織未來的 AI 藍圖:如果基礎架構仍以 GPU 優先配置、推論全部交給單一雲端供應商處理、資料治理政策也尚未觸及「推論發生在哪裡」這個層次——那麼當企業的 AI 應用全面走向任務式時,最先浮現的不會是效能問題,而是一套錯位的架構,在最需要擴展的時候,成為組織自己設下的瓶頸。
(本文授權非營利轉載,請註明出處:CIO Taiwan)
